Instructor: Jukka-Pekka Onnela
Unlike for “consumer software”, changes are often induced not by customer’s requirements, but rather by outcomes of the process along the way. For this reason, it is extremely valuable to design it in ways, which will not require a “total reconstruction”, if experimental evidence suggests a different path.
-- https://zerowithdot.com/improve-data-science-code/
Python - Interesting bits
(From course: "Using Python for Research", HarvardX PH526x)
Python can compare objects for value, as well as for identity, example:
In [9]: [2,3] == [2,3]
Out[9]: True
In [10]: [2,3] is [2,3]
Out[10]: False
In [11]: [2,3] is not [2,3]
Out[11]: True
Sequences in Python support slicing (in addition to negative indexing). Example:
In [3]: S = [1,2,3,4]
In [4]: S[0:2]
Out[4]: [1, 2]
Strings in Python are immutable.
It's common in Python for a list to contain values of only one type, but it's not strictly a requirement.
List methods are in-place methods – they don't return a value.
When dealing with tuples, the parentheses around them aren't strictly necessary - but they do increase clarity of expression.
For example, this is valid:
>>> x = 2,
>>> type(x)
tuple
When looping through a dict object, the key-value pairs are iterated over in an arbitrary order.
Keys in a dict must be objects of a type that is immutable. That means strings work, integers and floats also work, but lists and other dicts don't. Suprisingly, tuples also work, because they are immutable.
Some types in Python are immutable, like String. An object can be assigned to a variable. Eg.
a = 10
10 is an object of an immutable type. That means it does not have any methods that would change it. Yet, the variable named a can be reassigned:
a = 10
a = 11
Thus, some objects in Python have types that are immutable, but variables referring to those objects can be reassigned – and that doesn't violate the immutability of their type.
Scoping – LEGB:
- L: Local
- E: Enclosing function
- G: Global
- B: Built-in
An argument is an object that is passed to a function as its input; a paramemter, in contrast, is a variable that is used in the function definition to refer to that argument.
NumPy
Indexing creates a copy of the original array:
>>> z1 = np.array([1,3,5,7,9])
>>> ind = np.array([0,1,2])
>>> w = z1[ind]
>>> w[0] = 3
>>> w
array([3, 3, 5])
>>> z1
array([1, 3, 5, 7, 9])
Slicing creates a view on the original array:
>>> z1 = np.array([1,3,5,7,9])
>>> ind = np.array([0,1,2])
>>> w = z1[0:3]
>>> w[0] = 3
>>> w
array([3, 3, 5])
>>> z1
array([3, 3, 5, 7, 9])
Arrays can be indexed with vectors too:
>>> z1 = np.array([1,3,5,7,9])
>>> ind = [0,2,3]
>>> z1[ind]
array([1, 5, 7])
Publication-quality figures
Matplotlib has that capability – but its API is very large. For that reason, PyPlot is often used as a simplified interface to Matplotlib.
An instructor note I found intriguing:
Pyplot provides what is sometimes called a state–machine interface to matplot library.
Gamma distribution: a continuous probability density function that starts at 0 and goes all the way to positive infinity.
Testing
It's usually a good idea to start small, so instead of doing this 100 times, let us just first do it 5 times.
Faster random number generation
np.random.randint is much faster than Python's own random.randint. It can be over 10x faster, and in scientific computations that makes a big difference.
The code using NumPy is also shorter than the non-NumPy equivalent of below would be:
X = np.random.randint(1,7,(1000000,10))
Y = np.sum(X, axis=1)
plt.hist(Y);
Comparison of runtimes:
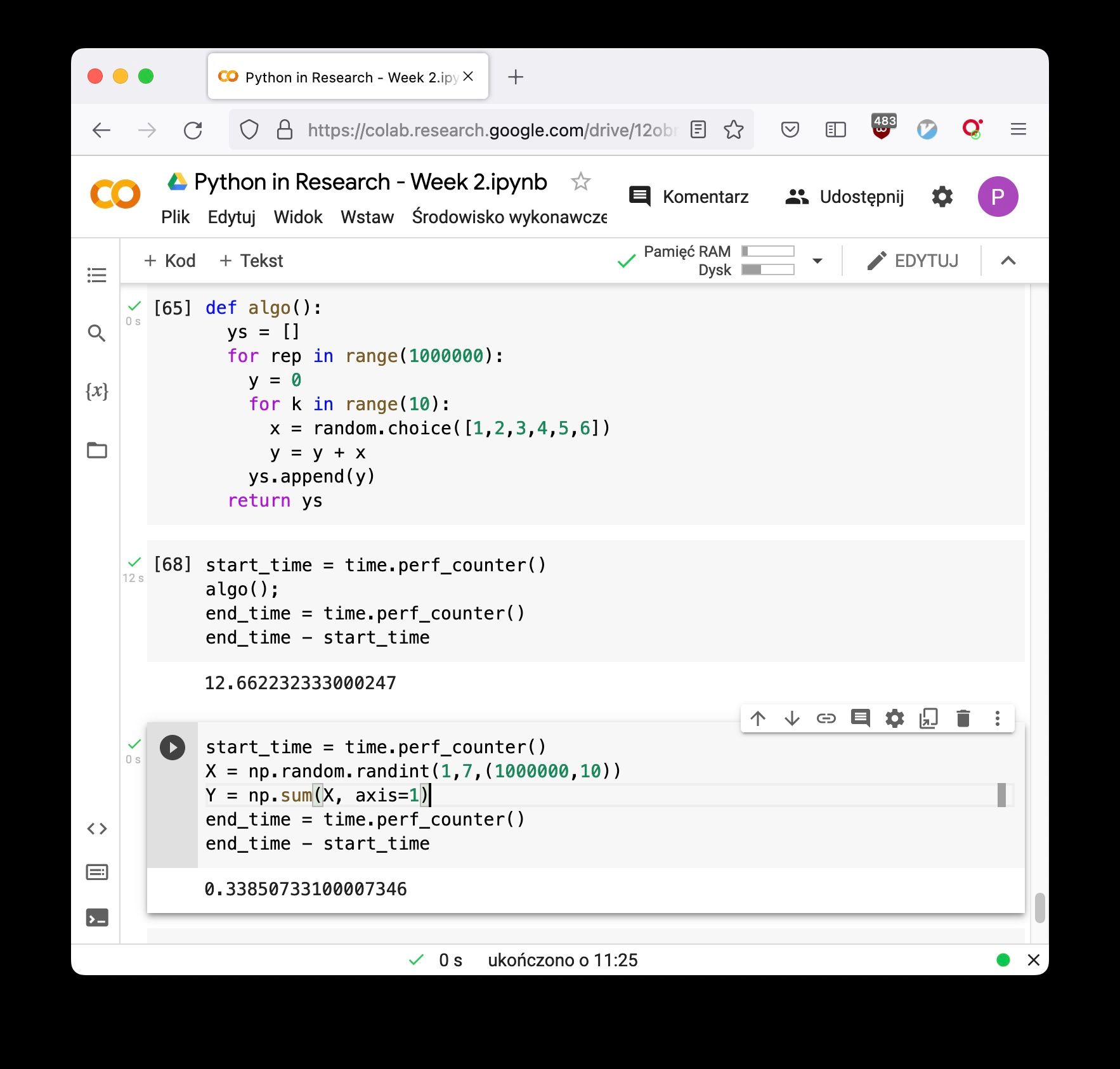
The speedup ("times faster") for the NumPy version is:
>>> 12.662232333000247/0.33850733100007346
37.40608008574414
Course overview
Source: https://courses.edx.org/courses/course-v1:HarvardX+PH526x+3T2016/4bdcc373b7a944f8861a3f190c10edca/
Week 3: Case Studies Part 1 (release December 6, 2016)
- Week 3 Overview
- DNA Translation (Comprehension Check)
- Homework: DNA Translation (Homework)
- Language Processing (Comprehension Check)
- Homework: Language Processing (Homework)
- Introduction to Classification (Comprehension Check)
- Homework: Introduction to Classification (Homework)
Week 4: Case Studies Part 2 (release December 6, 2016)
- Classifying Whiskies (Comprehension Check)
- Homework: Classifying Whiskies (Homework)
- Bird Migration (Comprehension Check)
- Homework: Bird Migration (Homework)
- Social Network Analysis (Comprehension Check)
- Homework: Social Network Analysis (Homework)
Notebooks
DocTest for notebooks - base code
%pip install -qq ipytest
#---
from doctest import run_docstring_examples as doctest
import ipytest
#---
ipytest.autoconfig()
Statistical learning
Common names for inputs: predictors, inependent variables, features, and variables.
Common names for outputs: response variables, dependent variables.
If the response is quantitative -- say, a number that measures weight or height, we call these problems regression problems. If the response is qualitative ‒ say, yes or no, or blue or green, we call these problems classification problems.
This specific method is known as the k-Nearest Neighbors classifier,
or kNN for short.Given a positive integer k, say 5, and a new data point, it first identifies those k points in the data that are nearest to the point and classifies the new data point as belonging to the most common class among those k neighbors.
"Majority vote" method is actually about plurality of the votes, because the most common vote does not need to represent a majority of votes.